

Generative Artificial Intelligence (GenAI) has made significant advancements in recent years, revolutionizing how companies leverage their data. GenAI models can generate human-like text and code, as well as creative content such as images, videos, and music, making them valuable tools across various industries. These capabilities help explain the current hype surrounding these technologies. According to many forecasts, GenAI could become one of the fastest-growing markets in the coming years. By analyzing large volumes of data and extracting valuable insights, GenAI enables companies to operate more efficiently and gain a competitive edge.
An impressive example of GenAI in action is the Allianz insurance company, which strategically uses generative AI to optimize internal processes. Specifically, the technology is successfully employed in processing pet insurance claims: the AI extracts relevant information from submitted invoices, verifies their accuracy, and ensures seamless further processing. This approach not only significantly reduces processing times but also allows employees to focus on more complex tasks [Source].
Generative AI has clear limitations, as it can only work with the data it was trained on and lacks access to company-specific information. This means that when asked a question like "How can I process my travel expense report?", the AI can only provide a generic answer since it has no knowledge of the internal processes or databases of a company.Retrieval-Augmented Generation (RAG) combines the capabilities of Large Language Models (LLMs) with the ability to specifically access data sources, such as an internal database. LLM stands for Large Language Model and belongs to the class of generative AI or generative language models. A RAG solution makes a significant difference for the user: instead of providing an imprecise, generic response, generative AI delivers specific information precisely tailored to the question. This maintains an intuitive user experience while making the results significantly more relevant and useful.
RAG is an innovative approach in the world of Generative Artificial Intelligence that combines the strengths of language models with efficient and precise information retrieval methods. At its core, RAG consists of two main components:
In this way, RAG systems can access current and specific information, making them particularly suitable for applications where accuracy and timeliness are essential, such as customer support or knowledge database chats.A successful example of RAG in action is the development of Genie, an on-call copilot by Uber. Genie uses generative AI to assist on-call engineers in communication and answering queries [Source].
Despite the promising advantages of RAG, there are several challenges and limitations that need to be addressed:
Such limitations can significantly affect the reliability and trustworthiness of RAG-based systems, especially in critical applications such as finance and law. For instance, Air Canada faced a legal dispute when a chatbot provided incorrect refund information to a customer in a bereavement case. The customer purchased a regular ticket based on this misinformation, and when the refund was later denied, the court ruled in favor of the customer. Such errors can lead to financial losses and severely damage trust in AI solutions [Source].
To minimize the impact of the above limitations, it is crucial to use robust evaluation methods that continuously monitor and measure the performance of RAG systems. One key solution is implementing evaluation frameworks such as Ragas. These frameworks offer structured approaches for developing metrics specifically tailored to the challenges of RAG systems.Regular evaluations with the Ragas framework provide insights into how well the RAG system performs in real-world scenarios and identify areas for improvement. These assessments enable proactive identification of weaknesses, allowing measures to be taken before minor issues escalate into significant challenges in customer interactions.
In this chapter, we take a detailed look at evaluating RAG systems using the Ragas Framework. The goal is to analyze the quality of Ragas evaluations, as these depend on configured parameters. To achieve this, we will examine the Context Precision metric of the Ragas framework. The investigation is based on experiments using the publicly available GermanDPR dataset.
The Ragas Framework was specifically developed to comprehensively evaluate and systematically improve RAG systems. It is based on three central evaluation approaches:
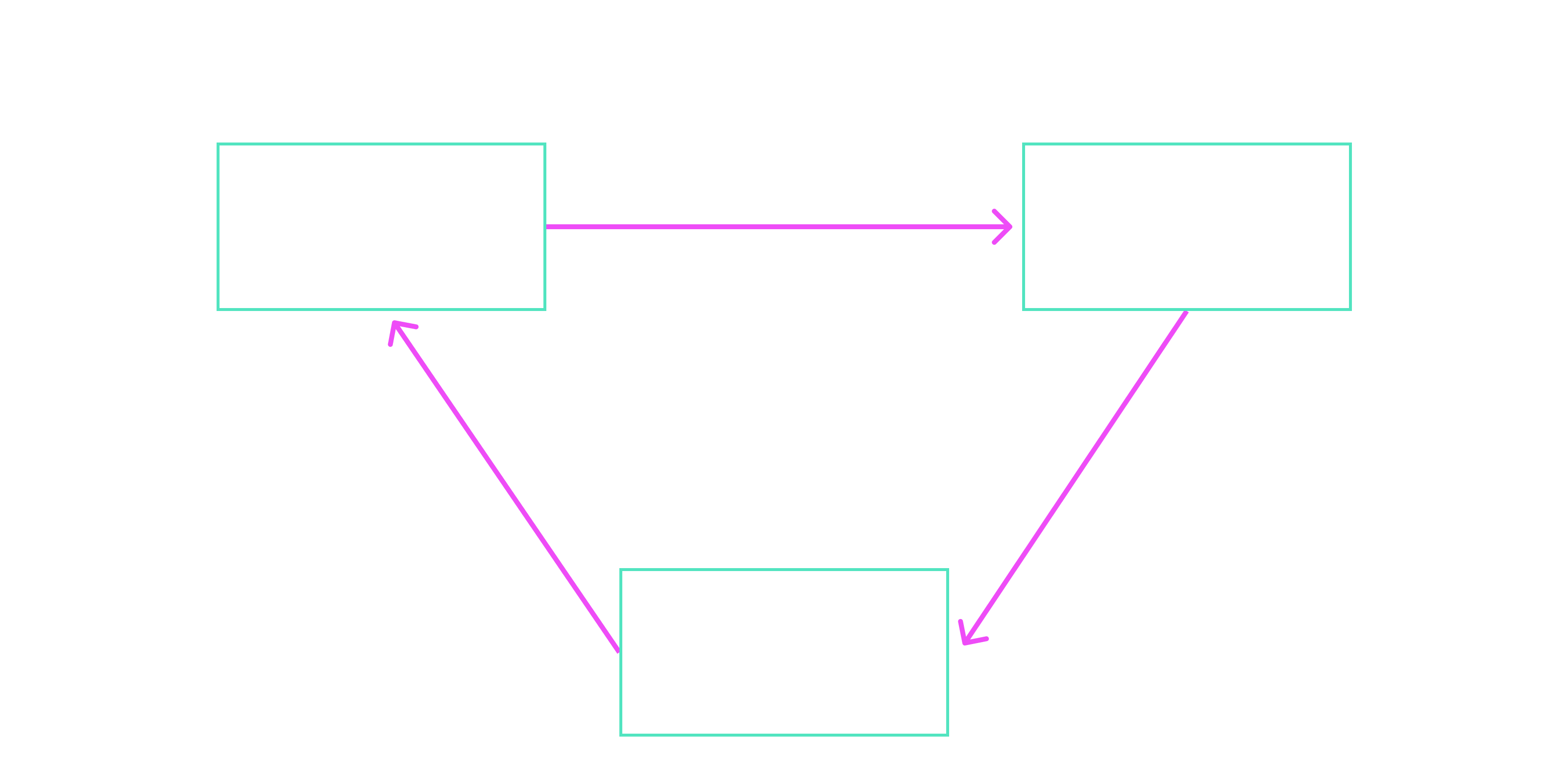
The triad of metrics is essential because it evaluates RAG systems holistically. Only if the retrieved context is relevant, the answer derived from the context, and the final response helpful, does the RAG system fulfill its purpose. A relevant context without an answer tied to it, or a correct answer irrelevant to the query, diminishes trust in the system's practical value. These metrics ensure that data and responses are optimally aligned with user needs.The Ragas Framework offers a flexible architecture adaptable to different datasets and language models. This makes it an effective tool for identifying weaknesses in RAG systems and implementing targeted improvements.
The RAG system generates an answer to a given question by retrieving relevant contexts from a database. The Context Precision metric evaluates whether the provided contexts are useful and relevant to the generated answer.
The Context Precision metric is a self-contained metric, meaning it uses an LLM to evaluate the retrieved contexts. The LLM is given a prompt input containing the question, the generated answer, the retrieved contexts, and the following instruction:
“Given question, answer, and context, verify if the context was useful in arriving at the given answer. Give verdict as '1' if useful and '0' if not with JSON output.”
The instruction at the end of the prompt is referred to as the Scorer Prompt, as the Context Precision metric is also called a scorer.
The wording, phrasing, and language of the Scorer Prompt influence the LLM's evaluation of Context Precision. For instance, if the question, answer, and context are in German but the Scorer Prompt is written in English, it may affect the evaluation results. Another factor is the choice of LLM, as different models have varying language proficiencies—for example, some LLMs are better at understanding German than others.
Based on these considerations, we identify the following parameters that influence the reliability of the Context Precision metric:
The GermanDPR dataset serves as the foundation for our evaluation and provides a realistic testing environment for German-language RAG systems. It contains a variety of questions, along with relevant (positive_ctxs) and irrelevant (hard_negative_ctxs) contexts. These relevant contexts act as references for assessing the system's output.
By combining relevant and irrelevant information, the dataset simulates real-world scenarios and serves as a reliable basis for analysis.
The structure of the GermanDPR dataset includes the following components:
This structure allows us to evaluate the performance of RAG systems in realistic scenarios by providing both relevant and irrelevant information.
Below is an example from the dataset:
Question: Wie viel Speicherplatz hat der iPod der zweiten Generation?
Answer: Neben dem Modell mit 1 GB auch in einer 2-GB-Version
Positive Contexts (positive_ctxs): [Context about the second-generation iPod]
Hard Negative Contexts (hard_negative_ctxs): [Context about the sixth-generation iPod]
The contexts in this example have been shortened.
To evaluate the Context Precision metric with different parameter settings, a RAG system was implemented using GPT-3.5 as the LLM and an Elasticsearch database with the OpenAI "text-embedding-3-small" embedding model as the retrieval system. The database was loaded with contexts from the GermanDPR dataset.
All questions from the dataset were then posed to the RAG system. During answer generation, the following intermediate results were saved for later evaluation.
In the Ragas framework, the Context Precision metric can be configured as follows:
1) The first step is selecting an LLM. In the following code snippet, GPT-3.5 Turbo from Azure OpenAI is used:
2) In the second step, the prompt is translated into German by our scorer:
The following class method can be used to evaluate the relevance of the extracted contexts.
The result returned by the scorer.single_turn_ascore(sample) method is a float value between 0 and 1. The higher the value, the more relevant the extracted contexts are.
Since the GermanDPR dataset also contains truly relevant contexts, we can assess whether the extracted contexts have a semantically similar content to the actual context.
In the example above, it becomes clear that the Context Precision Scorer evaluated all three extracted contexts as irrelevant to the answer generation. This can be observed in the values [0, 0, 0] in the Verdict column for the German-GPT3.5 Scorer. Additionally, the same values are shown in the Verdict column for the actual context, indicating that the scorer correctly identified the irrelevance of the contexts.
The above evaluation was performed for all questions available in the GermanDPR dataset using the following parameter combinations:
From the relevance evaluations provided by the differently configured scorers and the actual relevance of the contexts, standard metrics such as Precision, Recall, and F1-Score were calculated. These metrics enable us to represent the reliability of the Context Precision metricdepending on its configuration.
The evaluation of the configurations of the Context Precision Scorer is summarized in the following table:
The results clearly show that GPT-3.5 with German prompts achieved the highest overall performance, measured by an F1 score of 76.13%. While Claude 3 Haiku demonstrated a high recall value, it showed weaknesses in accuracy, indicating that irrelevant contexts were more frequently misclassified as relevant. Overall, scorers with prompts translated into German performed better, likely because the GermanDPR dataset contains exclusively German text. This highlights the importance of tailoring language models and prompts to the linguistic characteristics of a specific dataset to ensure the highest possible reliability of the Context Precision metric.
Summary
The analysis shows that both the choice of model and the language of the prompts are crucial for the effectiveness of the Context Precision metric of the Ragas framework. Particularly for German-language datasets and use cases, GPT-3.5 offers clear advantages. Organizations should therefore focus on language-specific adjustments and appropriate models to make optimal use of the Ragas framework. In practice, the framework has proven to be an effective tool for systematically evaluating and improving RAG systems.
From these findings, the following practical recommendations can be derived:
